فناوری جدید انویدیا صداهای هوش مصنوعی را به طبیعیترین حالت ممکن در میآورد
انویدیا اخیرا در کنفرانس Interspeech 2021 از نتایج تحقیقات و ابزارهایی رونمایی کرده که میتوانند شاخصههای گفتار طبیعی را به دست آورده و به شما اجازه دهند سیستمهای هوش مصنوعی را با صدای خود آموزش دهید.

به گزارش موبوایران، انویدیا اخیرا در کنفرانس Interspeech 2021 از نتایج تحقیقات و ابزارهایی رونمایی کرده که میتوانند شاخصههای گفتار طبیعی را به دست آورده و به شما اجازه دهند سیستمهای هوش مصنوعی را با صدای خود آموزش دهید.
تیم تحقیقاتی تبدیل متن به گفتار انویدیا برای بهبود ترکیب صدای هوش مصنوعی مدلی به نام RAD-TTS را توسعه داده که میتواند واقعگرایانهترین آواتارهای ممکن را بسازد. این سیستم میگذارد افراد مدلهای تبدیل متن به گفتار را با ویژگیهای مختلف صدای خود آموزش دهند.
یکی از قابلیتهای مدل RAD-TTS تبدیل صداست که به کاربر اجازه میدهد کلمات گوینده را با صدای شخص دیگری ادا کند. این رابط کنترل مناسب گام، طول و انرژی صدا را در اختیار فرد قرار میدهد. محققان انویدیا با استفاده از این فناوری برای سری ویدیوهای I Am AI روایتی صوتی ساختهاند که بیش از هر زمان دیگری شبیه صدای انسانهای واقعی است.
هدف از این کار دستیابی به روایتی بود که به لحن و سبک نمایش ویدیو نزدیک باشد. اکثر ویدیوهایی که با هوش مصنوعی روایت میشوند فعلا فاقد چنین کیفیتی هستند. ویدیوی حاضر نیز هنوز کمی رباتی به نظر میرسد اما بهتر از تمام هوش مصنوعیهایی است که تاکنون با آنها مواجه بودهاید.
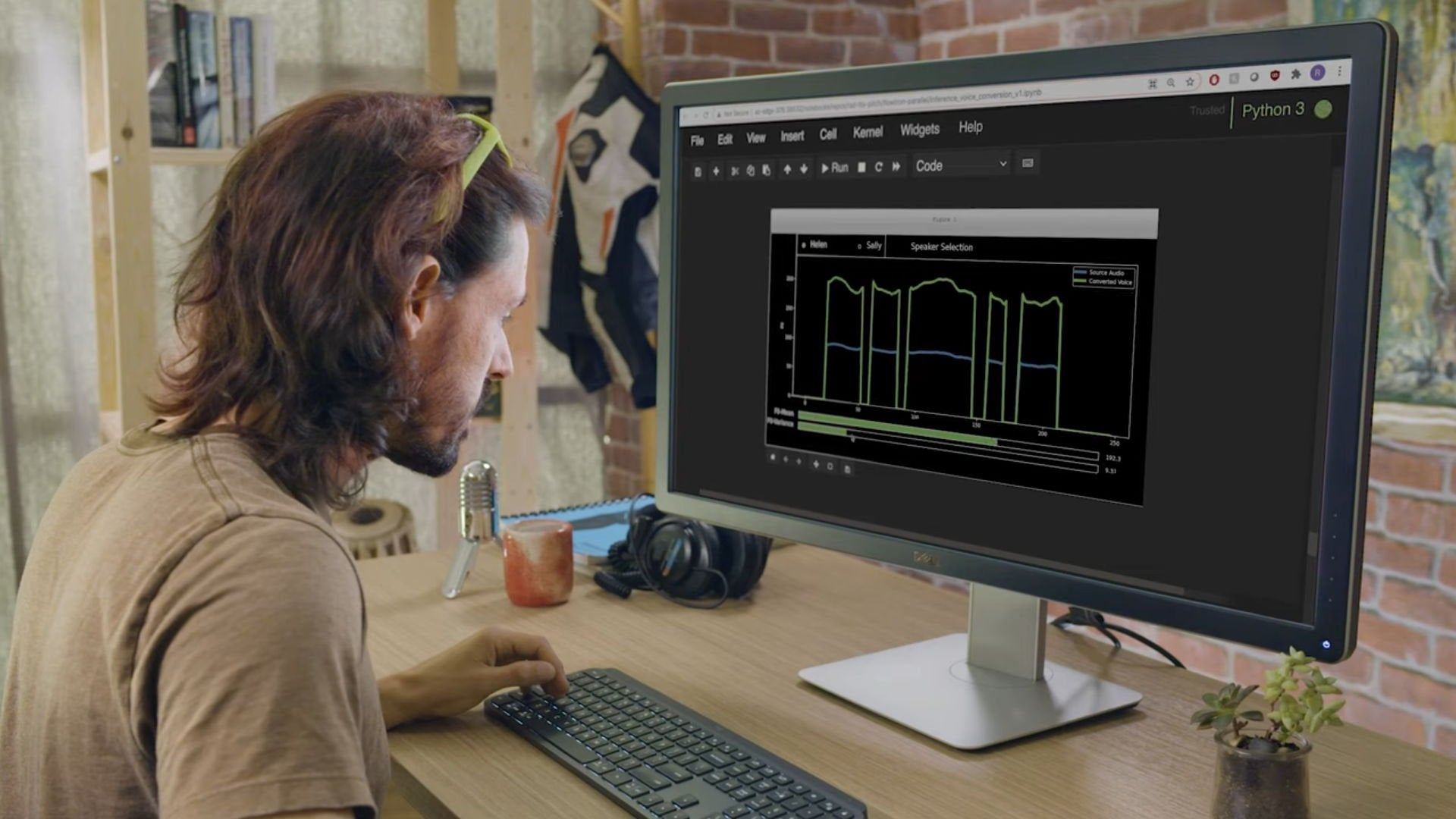
انویدیا میگوید: «تهیهکننده ویدیویی ما با این رابط میتواند خودش سناریوی ویدیو را ضبط کرده و بعد با کمک هوش مصنوعی صدا را به راوی زن تبدیل کند. سپس امکان دستیابی صدا و استفاده از حالتهای حسی مختلف، تاکید روی کلمات و اصلاح سرعت روایت در دسترس قرار میگیرد تا بهترین لحن روایی ایجاد شود.»
انویدیا نتایج تحقیقات خود را به صورت متن باز در اختیار کسانی قرار داده که مایل به انجام آزمایشهای مختلف در این حوزهاند. این شرکت میگوید: «شماری از این مدلها با هزاران ساعت صدا در سیستمهای NVIDIA DGX آموزش داده شدهاند. توسعهدهندگان میتوانند مدلهای مختلف را برای کاربردهای مختلف بهینهسازی کرده و سرعت یادگیری را با پردازندههای گرافیکی انویدیا Tensor Core افزایش دهند.»







